Unity UWA工具检测优化
性能优化大合集,请看下面的官方介绍
- UWA 优化百科向导: https://blog.uwa4d.com/archives/Index.html
- UWA Unity性能优化大合集,All In One ! https://blog.uwa4d.com/archives/allinone.html
- 如何看懂性能报告 https://blog.uwa4d.com/archives/Simple_PA_General.html
性能总结
- 查看这个性能分析图,性能总结–> https://www.uwa4d.com/demo/pa.html?v=5x&platform=android&name=jws&device=RedMiNote2
- 总体帧数:以一秒 30 帧为例,10 分钟测试,理想性能帧数可以跑到16000~18000帧,如果项目帧数低于这个范围,那么你的游戏可能正在经受一定的帧率卡顿问题,需要查看某一段时间内的性能瓶颈
- 总场景数
- GC次数:测试过程中系统垃圾回收操作(Garbage Collection)的调用次数,每次GC调用均会造成一定程度上的卡顿,降低了项目运行的流畅度,如果开发人员的逻辑代码分配堆内存过大过快的话,则GC调用的次数也会随之增加,标准为1000帧/次以上调用 GC,这个值越大调用一次 GC 越好.
- CPU均值:测试过程中平均每帧的CPU占用.高/中/低档的主流机型,设备性能越好,CPU耗时的均值肯定是越低
- CPU 占用(帧数占比):这个地方是 4 个图,CPU耗时超过33ms的帧数耗时超过了68%(请注意,UWA的建议是低于10%),超过50ms的帧数耗时达到35%.
- 总体 CPU 耗时走势:如果某条线特别高,需要看下是否可以进行优化,对比测试
- 总内存,堆内存优化:根据不同游戏进行不同的设定,定制一个合理的内存峰值才是正确的,也需要根据不同机器的性能评定.目前Unity所使用的Mono版本有这么个特点,Mono的堆内存一旦分配,就不会返还给系统.这意味着Mono的堆内存是只升不降的.IL2CPP版本在堆内存分配方面和Mono 最大的不同主要是Reserved Total 是可以下降的,而 Mono的 Reserved Total 只会上升不会下降.
- 关于任务列表:UWA 的测评报告还根据性能状态给出了优化任务列表,按照问题的严重程度设置了优先级,并对每个优化任务给出了需要检查或优化的步骤。
- 高 CPU 占用函数:
Camera.Render
UIPanel.LateUpdate()
UnityEngine.SetupCoroutine()
Animators.Update
Loading.UpdatePreloading
NavMeshManager
UICamera.Update()
UIRect.Update()
Physics.Processing
LoadingManager.Update()
Monobehaviour.OnMouse_
SystemInfoPrinter.Update()
TionManager.Update()
MeshSkinning.Update
AINormalWarrior.Update()
Physics.ProcessReports
SoundManager.Update()
Destroy
UIRect.Start()
TweenEffectBase.Update()
- 高堆内存分配函数:
UIPanel.LateUpdate()
UnityEngine.SetupCoroutine()
UICamera.Update()
TionManager.Update()
Physics.ProcessReports
LoadingManager.Update()
Animators.Update
BattleWinWnd.ShowContinueTip()
CheatManager.Update()
Destroy
UIRect.Start()
DynamicContent.Update()
EnemyHintAgent.Update()
Loading.UpdatePreloading
UIMessageBoxManager.Update()
GroupTutorialSystem.Update()
iTween.Update()
LevelManager.Update()
AINormalWarrior.Update()
PlayerBattleHUD.LateUpdate()
性能优化—CPU篇
- 查看这个性能分析图,总体性能趋势–> https://www.uwa4d.com/demo/pa.html?v=5x&platform=android&name=jws&device=RedMiNote2
- CPU方面的性能开销主要可归结为两大类:引擎模块性能开销(渲染模块、动画模块、物理模块、UI模块、粒子系统、加载模块和GC调用等等)和自身代码性能开销(第三方,以及 Unity 管理不到的内存)
- 渲染模块 :
(1)降低Draw Call,与维持总线带宽平衡,Draw Call是渲染模块优化方面的重中之重,一般来说,Draw Call越高,则渲染模块的CPU开销越大,降低Draw Call的方法则主要是减少所渲染物体的材质种类,并通过Draw Call Batching(https://docs.unity3d.com/Manual/DrawCallBatching.html)来减少其数量,游戏性能并非Draw Call越小越好,决定渲染模块性能的除了Draw Call之外,还有用于传输渲染数据的总线带宽.当我们使用Draw Call Batching将同种材质的网格模型拼合在一起时,可能会造成同一时间需要传输的数据(Texture、VB/IB等)大大增加,以至于造成带宽“堵塞”,在资源无法及时传输过去的情况下,GPU只能等待,从而反倒降低了游戏的运行帧率。Draw Call和总线带宽是天平的两端,我们需要做的是尽可能维持天平的平衡,任何一边过高或过低,对性能来说都是无益的。
(2) 简化资源,每帧渲染的三角形面片数、网格和纹理资源的具体使用情况
- 渲染模块 :
- UI 模块
在NGUI的优化方面,UIPanel.LateUpdate为性能优化的重中之重,它是NGUI中CPU开销最大的函数,没有之一.
对于UIPanel.LateUpdate的优化,主要着眼于UIPanel的布局,其原则如下:
- 尽可能将动态UI元素和静态UI元素分离到不同的UIPanel中(UI的重建以UIPanel为单位),从而尽可能将因为变动的UI元素引起的重构控制在较小的范围内;
- 尽可能让动态UI元素按照同步性进行划分,即运动频率不同的UI元素尽可能分离放在不同的UIPanel中;
- 控制同一个UIPanel中动态UI元素的数量,数量越多,所创建的Mesh越大,从而使得重构的开销显著增加。比如,战斗过程中的HUD运动血条可能会出现较多,此时,建议研发团队将运动血条分离成不同的UIPanel,每组UIPanel下5~10个动态UI为宜。这种做法,其本质是从概率上尽可能降低单帧中UIPanel的重建开销。
- 加载模块
加载模块的性能开销比较集中,主要出现于场景切换处(前一场景的场景卸载和下一场景的场景加载),且CPU占用峰值均较高
场景卸载情况下的 Destroy,引擎在切换场景时会收集未标识成“DontDestoryOnLoad”的GameObject及其Component,然后进行Destroy。同时,代码中的OnDestory被触发执行,这里的性能开销主要取决于OnDestroy回调函数中的代码逻辑。
场景卸载情况下的 Resources.UnloadUnusedAssets 一般情况下,场景切换过程中,该API会被调用两次,一次为引擎在切换场景时自动调用,另一次则为用户手动调用(一般出现在场景加载后,用户调用它来确保上一场景的资源被卸载干净)。在我们测评过的大量项目中,该API的CPU开销主要集中在500ms~3000ms之间。其耗时开销主要取决于场景中Asset和Object的数量,数量越多,则耗时越慢。
场景加载情况下的 资源加载,资源加载几乎占据了整个加载过程的90%时间以上,其加载效率主要取决于资源的加载方式(Resource.Load或AssetBundle加载)、加载量(纹理、网格、材质等资源数据的大小)和资源格式(纹理格式、音频格式等)等等。不同的加载方式、不同的资源格式,其加载效率可谓千差万别,所以我们在UWA测评报告中,特别将每种资源的具体使用情况进行展示,以帮助用户可以立刻查找到问题资源并及时进行改正。
场景加载情况下的 Instantiate实例化 :在场景加载过程中,往往伴随着大量的Instantiate实例化操作,比如UI界面实例化、角色/怪物实例化、场景建筑实例化等等。在Instantiate实例化时,引擎底层会查看其相关的资源是否已经被加载,如果没有,则会先加载其相关资源,再进行实例化,这其实是大家遇到的大多数“Instantiate耗时问题”的根本原因,这也是为什么我们在之前的AssetBundle文章中所提倡的资源依赖关系打包并进行预加载,从而来缓解Instantiate实例化时的压力(关于AssetBundle资源的加载,则是另一个很大的Story了,我们会在以后的AssetBundle加载技术专题中进行详细的讲解)
场景加载情况下的 SerializedField序列化开销 Instantiate实例化的性能开销还体现在脚本代码的序列化上,如果脚本中需要序列化的信息很多,则Instantiate实例化时的时间亦会很长。最直接的例子就是NGUI,其代码中存在很多SerializedField标识,从而在实例化时带来了较多的代码序列化开销。因此,在大家为代码增加序列化信息时,这一点是需要大家时刻关注的- 代码效率
性能开销都遵循着“二八原则”,即80%的性能开销都集中在20%的函数上
Camera.Render
MovementScript.FixedUpdate()
ParticleSystem.Update
Physics.Simulate
TerrainManager.LoadTerrainObject()[Coroutine:MoveNext]
TerrainManager.LoadTerrainSplices()[Coroutine:MoveNext]
ParticleSystem.WaitForUpdateThreads()
GameStarter.Update()
等等
性能优化,进无止境-内存篇
- 1 内存的开销无外乎以下三大部分:1.Unity资源内存占用;2. Unity引擎模块自身内存占用;3.Unity用户管理内存;4.第三方插件内存(比如 toLua),不属于Unity 。
一:资源内存占用
在一个较为复杂的大中型项目中,资源的内存占用往往占据了总体内存的70%以上.纹理(Texture)、网格(Mesh)、动画片段(AnimationClip)、音频片段(AudioClip)、材质(Material)、着色器(Shader)、字体资源(Font)以及文本资源(Text Asset)等等.其中,纹理、网格、动画片段和音频片段则是最容易造成较大内存开销的资源纹理
- 纹理资源可以说是几乎所有游戏项目中占据最大内存开销的资源,一个6万面片的场景,网格资源最大才不过10MB,但一个2048x2048的纹理,可能直接就达到16MB.需要优化的点
纹理格式:Android平台的ETC、iOS平台的PVRTC、Windows PC上的DXT,具体的采用何种方式对纹理进行操作需要根据项目情况来看.
在使用硬件支持的纹理格式时,你可能会遇到以下几个问题:- 色阶问题,由于ETC、PVRTC等格式均为有损压缩,因此,当纹理色差范围跨度较大时,均不可避免地造成不同程度的“阶梯”状的色阶问题。因此,很多研发团队使用RGBA32/ARGB32格式来实现更好的效果。但是,这种做法将造成很大的内存占用。比如,同样一张1024x1024的纹理,如果不开启Mipmap,并且为PVRTC格式,则其内存占用为512KB,而如果转换为RGBA32位,则很可能占用达到4MB。所以,研发团队在使用RGBA32或ARGB32格式的纹理时,一定要慎重考虑,更为明智的选择是尽量减少纹理的色差范围,使其尽可能使用硬件支持的压缩格式进行储存。
- ETC1 不支持透明通道问题,在Android平台上,对于使用OpenGL ES 2.0的设备,其纹理格式仅能支持ETC1格式,该格式有个较为严重的问题,即不支持Alpha透明通道,使得透明贴图无法直接通过ETC1格式来进行储存。对此,我们建议研发团队将透明贴图尽可能分拆成两张,即一张RGB24位纹理记录原始纹理的颜色部分和一张Alpha8纹理记录原始纹理的透明通道部分。然后,将这两张贴图分别转化为ETC1格式的纹理,并通过特定的Shader来进行渲染,从而来达到支持透明贴图的效果。该种方法不仅可以极大程度上逼近RGBA透明贴图的渲染效果,同时还可以降低纹理的内存占用,是我们非常推荐的使用方式。建议:尽量采用 ETC2,在 Android 设备支持OpenGL ES 3.0的上面进行市场分流
- 纹理资源可以说是几乎所有游戏项目中占据最大内存开销的资源,一个6万面片的场景,网格资源最大才不过10MB,但一个2048x2048的纹理,可能直接就达到16MB.需要优化的点
- 纹理尺寸,一般来说,纹理尺寸越大,则内存占用越大。尽可能降低纹理尺寸,如果512x512的纹理对于显示效果已经够用,那么就不要使用1024x1024的纹理.
- Mipmap功能,Mipmap旨在有效降低渲染带宽的压力,提升游戏的渲染效率.开启Mipmap会将纹理内存提升1.33倍.对于具有较大纵深感的3D游戏来说,3D场景模型和角色我们一般是建议开启Mipmap功能的.但是经常会发现部分UI纹理也开启了Mipmap功能,这其实就没有必要的,绝大多数UI均是渲染在屏幕最上层,开启Mipmap并不会提升渲染效率,反倒会增加无谓的内存占用.
- Read & Write 一般情况下,纹理资源的“Read & Write”功能在Unity引擎中是默认关闭的。项目深度优化时发现了不少项目的纹理资源会开启该选项,
网格
- Normal、Color和Tangent,Mesh资源的数据中经常会含有大量的Color数据、Normal数据和Tangent数据,这些数据的存在将大幅度增加Mesh资源的文件体积和内存占用.Color数据和Normal数据主要为3DMax、Maya等建模软件导出时设置所生成,而Tangent一般为导入引擎时生成.更为麻烦的是,如果项目对Mesh进行Draw Call Batching操作的话,那么将很有可能进一步增大总体内存的占用.比如,100个Mesh进行拼合,其中99个Mesh均没有Color、Tangent等属性,剩下一个则包含有Color、Normal和Tangent属性,那么Mesh拼合后,CombinedMesh中将为每个Mesh来添加上此三个顶点属性,进而造成很大的内存开销。需要查看该模型的渲染Shader中是否需要这些数据进行渲染
二:引擎模块自身占用
- 引擎自身中存在内存开销的部分纷繁复杂,可以说是由巨量的“微小”内存所累积起来的,GameObject及其各种Component(最大量的Component应该算是Transform了),ParticleSystem、MonoScript以及各种各样的模块Manager(SceneManager、CanvasManager、PersistentManager等)…
一般情况下,上面所指出的引擎各组成部分的内存开销均比较小,真正占据较大内存开销的是这两处:WebStream SerializedFile ,其绝大部分的内存分配则是由AssetBundle加载资源所致,当使用new WWW或CreateFromMemory来加载AssetBundle时,Unity引擎会加载原始数据到内存中并对其进行解压,而WebStream的大小则是AssetBundle原始文件大小 + 解压后的数据大小 + DecompressionBuffer(0.5MB).
当你使用LoadFromCacheOrDownload、CreateFromFile或new WWW本地AssetBundle文件时产生的序列化文件.
- 是否存在AssetBundle没有被清理干净的情况。开发团队可以通过Unity Profiler直接查看其使用具体的使用情况,并确定Take Sample时AssetBundle的存在是否合理;
- 对于占用WebStream较大的AssetBundle文件(如UI Atlas相关的AssetBundle文件等),建议使用LoadFromCacheOrDownLoad或CreateFromFile来进行替换,即将解压后的AssetBundle数据存储于本地Cache中进行使用。这种做法非常适合于内存特别吃紧的项目,即通过本地的磁盘空间来换取内存空间。
- AssetBundle管理机制:https://blog.uwa4d.com/archives/ABTheory.html
三:托管堆内存占用
- 托管堆内存占用,不管是 Mono 版本还是 IL2CPP 版本,这里叫的方便一点,称为 Unity 内置托管虚拟机,其托管堆内存是由Unity 内置托管虚拟机分配和管理的。“托管” 的本意是Unity 内置托管虚拟机可以自动地改变堆的大小来适应你所需要的内存,并且适时地调用垃圾回收(Garbage Collection)操作来释放已经不需要的内存,从而降低开发人员在代码内存管理方面的门槛。
- 用户不必要的堆内存分配主要来自于以下几个方面:
- 高频率地 New Class/Container/Array等。研发团队切记不要在Update、FixUpdate或较高调用频率的函数中开辟堆内存,这会对你的项目内存和性能均造成非常大的伤害。做个简单的计算,假设你的项目中某一函数每一帧只分配100B的堆内存,帧率是1秒30帧,那么1秒钟游戏的堆内存分配则是3KB,1分钟的堆内存分配就是180KB,10分钟后就已经分配了1.8MB。如果你有10个这样的函数,那么10分钟后,堆内存的分配就是18MB,这期间,它可能会造成Mono的堆内存峰值升高,同时又可能引起了多次GC的调用。在我们的测评项目中,一个函数在10分钟内分配上百MB的情况比比皆是,有时候甚至会分配上GB的堆内存。
- Log输出。我们发现在大量的项目中,仍然存在大量Log输出的情况。建议研发团队对自身Log的输出进行严格的控制,仅保留关键Log,以避免不必要的堆内存分配。对此,我们在UWA测评报告中对Log的输出进行了详细的检测,不仅提供详细的性能开销,同时占用Log输出的调用路径。这样,研发团队可直接通过报告定位和控制Log的输出。
- UIPanel.LateUpdate。这是NGUI中CPU和堆内存开销最大的函数。它本身只是一个函数,但NGUI的大量使用使它逐渐成为了一个不可忽视规则。该函数的堆内存分配和自身CPU开销,其根源上是一致的,即是由UI网格的重建造成。因此,其对应的优化方法是直接查看CPU篇中的UI模块讲解。(1:动静分离在不同的 UIPanel 中,每组UIPanel下5~10个动态UI为宜)
- String连接、部分引擎API(GetComponent)的使用 等等
内存占用标准
- 某些渠道对Android游戏的PSS内存进行了严格的限制。一般要求游戏的PSS内存在200MB以下。这是我们将Reserved Total内存设定在150MB的另外一个重要原因。(旧)
pss内存:进程的内存占用情况.有一些内存是多个进程共享的,我们计算的时候如果把这些计算进去进程的内存占用,显然会多算。
pss的意思是进程自己独自占有的+共享的/共享的数目。
因此如果进程有自己独立的内存100M,和另外一个进程共享10M。
那么pss就是100 + 10/2=105- 较为合理的内存分配额度
纹理资源 0.33 内存资源
网格资源 0.13 内存资源
动画片段 0.1 内存资源
音频片段 0.1 内存资源
Mono内存 0.26 内存资源
其他 0.06 内存资源
其中如果是 IL2CPP 版本的话,内存是可以返还给系统的,则无需按照这个分配额度进行分配
四:内存泄露
- 内存泄露的误区:
- 误区一
我的项目进出场景前后内存回落不一致,比如进入场景后,内存增加40MB,出来后下降30MB,仍有10MB内存没有返回给系统,即说明内存存在泄露情况。- 误区二
我的项目在进出场景前后,Unity Profiler中内存回落正常,但Android的PSS数值并没有完全回落(出场景后的PSS值高于进场景前的PSS值),即说明内存存在泄露情况。- 以上两种情况均不能表明内存存在泄漏问题,造成内存不能完全回落的情况有很多,资源加载后常驻内存以备后续使用,Mono堆内存的只升不降等等,这些均可造成内存无法完全回落
五:检查资源的使用情况,特别是纹理、网格等资源的使用
- 资源泄漏是内存泄露的主要表现形式,其具体原因是用户对加载后的资源进行了储存(比如放到Container中),但在场景切换时并没有将其Remove或Clear,从而无论是引擎本身还是手动调用Resources.UnloadUnusedAssets等相关API均无法对其进行卸载,进而造成了资源泄露。对于这种情况的排查相当困难,这是因为项目中的资源量过于巨大,泄露资源往往很难定位
- UWA 推出通过资源的“生命周期”属性来快速查看有哪些资源是“常驻”内存的,并且判断该资源是“预加载”资源还是“泄露”资源.推出了资源的“场景比较”功能。建议大家通过以下两种方式进行资源比较,以便更快地找到存在“泄露”问题的资源.
一般来说,同种场景或同一场景的资源使用应该是较为固定的,比如游戏项目中的主城场景或主界面场景。通过比较不同时刻同一场景的资源信息,可以快速帮你找到其资源使用的差异情况。这样,你只需判断这些“差异”资源的存在是否合理,即可快速判定是否存在资源泄露,已经具体的泄露资源。
除一些常驻资源外,不同类型的场景,其资源使用是完全不同的。比如,游戏中主城和战斗副本的资源,除少部分常驻内存的资源外,二者使用的绝大部分资源应该是不一致的。所以,通过比较两种不同类型的场景,你可以直接查看比较结果中的“共同资源”,并判断其是否确实为预先设定好的常驻资源。如果不是,则它很可能是“泄露”资源,需要你进一步查看项目的资源管理是否存在漏洞。
六:通过Profiler来检测WebStream或SerializedFile的使用情况
- AssetBundle的管理不当也会造成一定的内存泄露,即上一场景中使用的AssetBundle在场景切换时没有被卸载掉,而被带入到了下一场场景中。对于这种情况,建议直接通过Profiler Memory中的Take Sample来对其进行检测,通过直接查看WebStream或SerializedFile中的AssetBundle名称,即可判断是否存在“泄露”情况。
七:通过Android PSS/iOS Instrument反馈的App线程内存来查看
- Unity Profiler中内存回落正常,但Android的PSS数值并没有完全回落”是有可能的,这是因为Unity Profiler反馈的是引擎的真实分配的物理内存,而PSS中记录的则包括系统的部分缓存。一般情况下,Android或iOS并不会及时将所有App卸载数据进行清理,为了保证下次使用时的流畅性,OS会将部分数据放入到缓存,待自身内存不足时,OS Kernel会启动类似LowMemoryKiller的机制来查询缓存甚至杀死一些进程来释放内存.
我们推荐的测试方式是在两个场景之间来回不停切换,比如主城和战斗副本间。理论上来说,多次切换同样的场景,如果Profiler中显示的Unity内存回落正常,那么其PSS/Instrument的内存数值波动范围也是趋于稳定的,但如果出现了PSS/Instrument内存持续增长的情况,则需要大家注意了。这可能有两种可能:
Unity引擎自身的内存泄露问题。这种概率很小,之前仅在少数版本中出现过。
第三方插件在使用时出现了内存泄露。这种概率较大,因为Profiler仅能对Unity自身的内存进行监控,而无法检测到第三方库的内存分配情况。因此,在出现上述内存问题时,建议大家先对自身使用的第三方库进行排查。
八:无效的Mono堆内存开销
- 无效的Mono堆内存。它是Mono所分配的堆内存,但却没有被真正利用上,因此称之为“无效”,如何查看我的项目中是否存在较大量的“无效堆内存”呢?
UWA测评报告中:蓝线的Reserved Total为当前项目所占据的总物理内存,而紫线的Used Total为当前项目所使用的总物理内存不一致,Reserved Total - Used Total为空闲内存,而这其中主要由两部分组成,空闲的Unity引擎内存和无效的Mono堆内存.
我们应该如何避免或减少过多“无效堆内存”的分配呢?
- 避免一次性堆内存的过大分配。Mono的堆内存也是“按需”逐步进行分配的。但如果一次性开辟过大堆内存,比如New一个较大Container、加载一个过大配置文件等,则势必会造成Mono的堆内存直接冲高,所以研发团队对堆内存的分配需要时刻注意;
- 避免不必要的堆内存开销。UWA测评报告中将项目运行过程中堆内存分配Top10函数进行罗列,限于篇幅,我们不再此处进行一一赘述,研发团队可以直接查看之前一篇的内存优化相关文章。
九:资源冗余
在内存管理方面,还有一个大家必须关注的话题——资源冗余。在我们测评过的大量项目中,95%以上的项目均存在不同程度的资源冗余情况。所谓“资源冗余”,是指在某一时刻内存中存在两份甚至多份同样的资源。导致这种情况的出现主要有两种原因:
- 1、AssetBundle打包机制出现问题.同一份资源被打入到多份AssetBundle文件中。举个例子,同一张纹理被不同的NPC所使用,同时每个NPC被制作成独立的AssetBundle文件,那么在没有针对纹理进行依赖打包的前提下,就会出现该张纹理出现在不同的NPC AssetBundle文件中。当这些AssetBundle先后被加载到内存后,内存中即会出现纹理资源冗余的情况。对此,我们建议研发团队在发现资源冗余问题后,对相关AssetBundle的制作流程一定要进行检查。同时,我们在UWA测评中为每个资源引入了一个衡量指标——“数量峰值”。它指的是同一资源在同一帧中出现的最大数量。如果大于1,则说明该资源很可能存在 “冗余资源”。大家可以通过这一列进行排序,即可立即查看项目中的资源冗余情况。
- 2.资源的实例化所致.在Unity引擎中,当我们修改了一些特定GameObject的资源属性时,引擎会为该GameObject自动实例化一份资源供其使用,比如Material、Mesh等。以Material为例,我们在研发时经常会有这样的做法:在角色被攻击时,改变其Material中的属性来得到特定的受击效果。这种做法则会导致引擎为特定的GameObject重新实例化一个Material,后缀会加上(instance)字样。其本身没有特别大的问题,但是当有改变Material属性需求的GameObject越来越多时(比如ARPG、MMORPG、MOBA等游戏类型),其内存中的冗余数量则会大量增长。如下图所示,随着游戏的进行,实例化的Material资源会增加到333个。虽然Material的内存占用不大,但是过多的冗余资源却为Resources.UnloadUnusedAssets API的调用效率增加了相当大的压力。
一般情况下,资源属性的改变情况都是固定的,并非随机出现。比如,假设GameObject受到攻击时,其Material属性改变随攻击类型的不同而有三种不同的参数设置。那么,对于这种需求,我们建议你直接制作三种不同的Material,在Runtime情况下通过代码直接替换对应GameObject的Material,而非改变其Material的属性。这样,你会发现,成百上千的instance Material在内存中消失了,取而代之的,则是这三个不同的Material资源
性能优化,AssetBundle 打包
- https://blog.uwa4d.com/archives/ABtopic_2.html
- 唯一API,BuildPipeline.BuildAssetBundles,引擎将自动根据资源的assetbundleName属性(以下简称abName)批量打包,自动建立Bundle以及资源之间的依赖关系。
- 打包规则,在资源的Inpector界面最下方可设置一个abName,每个abName(包含路径)对应一个Bundle,即abName相同的资源会打在一个Bundle中。如果所依赖的资源设置了不同的abName,则会与之建立依赖关系,避免出现冗余。支持增量式发布,即在资源内容改变并重新打包时,会自动跳过内容未变的Bundle。因此,相比4.x,会极大地缩短更新Bundle的时间。
- 5.x下默认开启的三个选项(CompleteAssets ,用于保证资源的完备性;CollectDependencies,用于收集资源的依赖项;DeterministicAssetBundle,用于为资源维护固定ID.对于移动平台,5.x下默认会将TypeTree信息写入AssetBundle,因此在移动平台上DisableWriteTypeTree选项也变得有意义了.
- Manifest文件,5.x中的依赖关系,在打包后生成的文件夹中,每个Bundle都会对应一个manifest文件,记录了Bundle的一些信息,但这类manifest只在增量式打包时才用到;同时,根目录下还会生成一个同名manifest文件及其对应的Bundle文件,通过该Bundle可以在运行时得到一个AssetbundleManifest对象,而所有的Bundle以及各自依赖的Bundle都可以通过该对象提供的接口进行获取.即你打包输出的一个文件里面有个同名的 xxx 和一个 xxx.manifest 通过这2个文件你可以获取到一个AssetbundleManifest对象,用于取出各个 AB 包的依赖关系
- Variant参数,就是Inpector界面最下方最右侧的名字,Variant参数能够让AssetBundle方便地进行“多分辨率支持”,打包时,Variant会作为后缀添加在Bundle名字之后。相同abName,不同variant的Bundle中,资源必须是一一对应的,且他们在Bundle中的ID也是相同的,从而可以起到相互替换的作用。当需要为手机和平板上的某个UI界面使用两套分辨率不同的纹理、Shader,以及文字提示时,借助Variant的特性,只需创建两个文件夹,分别放置两套不同的资源,且资源名一一对应,然后给两个文件夹设置相同的abName和不同的variant,再给UI界面设置abName,然后进行打包即可。运行时,先选择合适的依赖包加载,那么后续加载UI界面时,会根据已加载的依赖包,呈现出相对应的版本。
- abName可通过脚本进行设置和清除,也可以通过构造一个AssetBundleBuild数组来打包。
- 开启DisableWriteTypeTree可能造成AssetBundle对Unity版本的兼容问题,但会使Bundle更小,同时也会略微提高加载速度。
- Prefab之间不会建立依赖,即如果Prefab-A和Prefab-B引用了同一张纹理,而他们设置了不同的abName,而共享的纹理并未设置abName,那么Prefab-A和Prefab-B可视为分别打包,各自Bundle中都包含共享的纹理。因此在使用UGUI,开启Sprite Packer时,由于Atlas无法标记abName,在设置UI界面Prefab的abName时就需要注意这个问题。
- 5.x中加入了Shader stripping功能,在打包时,默认情况下会根据当前场景的Lightmap及Fog设置对资源中的Shader进行代码剥离。这意味着,如果在一个空场景下进行打包,则Bundle中的Shader会失去对Lightmap和Fog的支持,从而出现运行时Lightmap和Fog丢失的情况.而通过将Edit->Project Settings->Graphics下shader Stripping中的modes改为Manual,并勾选相应的mode即可避免这一问题。
Android平台的代码热更新
Android平台的代码热更新,该原理是解除资源和代码的关系,将代码编译成dll,在游戏一运行时动态加载。
- 分离.对于脚本我们可以简单地将脚本分为数据(变量)和逻辑(方法)两部分:例如A.cs -> Uwa4dDataA.cs和Uwa4dLogicA.cs。其中Uwa4dDataA.cs中只有成员变量而Uwa4dLogicA.cs和A.cs基本一致。分离后的问题是,依赖了A.cs的资源再也找不到A.cs。因为二者之间的依赖是通过资源文件保存的,所以只需要将资源文件的对于A.cs的依赖替换成 Uwa4dDataA.cs的依赖即可。
- 将Uwa4dLogicA.cs编译成Dll,首先将Uwa4dDataA.cs编译成Assembly-CSharp.dll,然后编译Uwa4dLogicA.cs(依赖Assembly-CSharp.dll),另外要注意编译时.Net的兼容版本。
- 加载Uwa4dLogicA.cs
加载Uwa4dLogicA.cs编译后的DLL,获得Uwa4dLogicA.cs后通过AddComponent将其挂在相应的资源上,并利用Uwa4dDataA.cs对于其数据进行初始化。
Unity纹理加载
资源加载、资源卸载、Object的实例化和代码的序列化是最耗时的
- 资源加载,资源加载是加载模块中最为耗时的部分,CPU开销在Unity引擎中主要体现在Loading.UpdatePreloading和Loading.ReadObject两项中.
- Loading.UpdatePreloading,这一项仅在调用类似LoadLevel(Async)的接口处出现,主要负责卸载当前场景的资源,并且加载下一场景中的相关资源和序列化信息等.下一场景中,自身所拥有的GameObject和资源越多,其加载开销越大。
- 在很多项目中,存在另外一种加载方式,即场景为空场景,绝大部分资源和GameObject都是通过OnLevelWasLoaded回调函数中进行加载、实例化和拼合的。对于这种情况,Loading.UpdatePreloading的加载开销会很小。
- Loading.ReadObject,这一项记录的则是资源加载时的真正资源读取性能开销,基本上引擎的主流资源(纹理资源、网格资源、动画片段等等)读取均是通过该项来进行体现。可以说,这一项很大程度上决定了项目场景的切换效率。正因如此,我们就当前项目中所用的主流资源进行了大量的测试和分析,下面我们将分析结果与大家一起分享,希望可以帮到正在进行开发的你。
- 纹理资源,纹理资源是项目加载过程中开销占用最大的资源之一,其加载效率由其自身大小决定。决定纹理资源大小的因素主要有三种:分辨率、格式和Mipmap是否开启。
- 分辨率和格式是影响纹理资源加载效率的重要因素,因为这两项的设置对纹理资源的大小影响很大。1、纹理资源的分辨率对加载性能影响较大,分辨率越高,其加载越为耗时。设备性能越差,其耗时差别越为明显;2、设备越好,加载效率确实越高。但是,对于硬件支持纹理(ETC1/PVRTC)来说,中高端设备的加载效率差别已经很小,比如图中的红米Note2和三星S6设备,差别已经很不明显。
- 纹理资源的格式对加载性能影响同样较大,Android平台上,ETC1和ETC2的加载效率最高。同样,iOS平台上,PVRTC 4BPP的加载效率最高。
- RGBA16格式纹理的加载效率同样很高,与RGBA32格式相比,其加载效率与ETC1/PVRTC非常接近,并且设备越好,加载开销差别越不明显;
- RGBA32格式纹理的加载效率受硬件设备的性能影响较大,ETC/PVRTC/RGBA16受硬件设备的影响较低。
- 这里需要指出的是测试中所使用的ETC1和ETC2纹理均为RGB 4Bit格式,所以对于半透明纹理贴图,需要两张ETC1格式的纹理进行支持(一张RGB通道,一张Alpha通道)。逐一加载两张ETC1格式的纹理,其加载效率要低于RGBA16格式,但可以通过加载方式来进行弥补.
- 开启Mipmap功能,开启Mipmap功能同样会增大一部分纹理大小,一般来说,其内存会增加至原始大小的1.33倍。开启Mipmap功能会导致资源加载更为耗时,且设备性能越差,其加载效率影响越大.
- 1、严格控制RGBA32和ARGB32纹理的使用,在保证视觉效果的前提下,尽可能采用“够用就好”的原则,降低纹理资源的分辨率,以及使用硬件支持的纹理格式。
- 2、在硬件格式(ETC、PVRTC)无法满足视觉效果时,RGBA16格式是一种较为理想的折中选择,既可以增加视觉效果,又可以保持较低的加载耗时。
- 3、严格检查纹理资源的Mipmap功能,特别注意UI纹理的Mipmap是否开启。在UWA测评过的项目中,有不少项目的UI纹理均开启了Mipmap功能,不仅造成了内存占用上的浪费,同时也增加了不小的加载时间。
- 4、ETC2对于支持OpenGL ES3.0的Android移动设备来说,是一个很好的处理半透明的纹理格式。但是,如果你的游戏需要在大量OpenGL ES2.0的设备上进行运行,那么我们不建议使用ETC2格式纹理。因为不仅会造成大量的内存占用(ETC2转成RGBA32),同时也增加一定的加载时间。下图为测试2中所用的测试纹理在三星S3和S4设备上加载性能表现。可以看出,在OpenGL ES2.0设备上,ETC2格式纹理的加载要明显高于ETC1格式,且略高于RGBA16格式纹理。因此,建议研发团队在项目中谨慎使用ETC2格式纹理。
Unity网格加载模块
- 网格资源,网格资源与纹理资源一样,在加载时同样会造成较高的CPU占用,且其加载效率由其自身大小(网格数据量)决定。
- 不同面片数的网格资源加载效率测试,1、资源的数据量对加载性能影响较大,面片数越多,其加载越为耗时。设备性能越差,其耗时差别越为明显;2、随着硬件设备性能的提升,其加载效率差异越来越不明显。
- 相同面片数、不同顶点属性的加载效率测试,1、顶点属性的增加对内存和AssetBundle包体大小影响较大。与测试1中未引入Tangent顶点属性的网格数据相比,测试2中的网格数据在内存上均大幅度增加(增加量与网格顶点数有关),且AssetBundle大小同样有成倍(1~2)的增加。2、顶点属性增加对于加载效率影响较大,且顶点数越多,影响越大。
- 模型常见的顶点属性主要有Position、UV、Normal、Tangent和Color。Color属性与Tangent属性一样,如果网格顶点拥有该属性,同样会对内存、物理体积和加载性能造成影响。在使用Draw Call Batching时,不要将不同属性的网格模型拼合在一起。在使用Draw Call Batching时,切忌将不同属性的网格模型拼合在一起。举个例子 ,100个网格模型进行Static Batching,如果99个模型只有Position和UV两种属性,而剩下1个模型函数有Position、UV、Normal、Tangent和Color五种属性。那么引擎在进行拼合时,会将前99个模型的顶点属性补齐,然后再进行拼合。这样无形中会增加大量的内存占用,从而造成不必要的内存浪费。
- 开启/关闭Read/Write功能的加载效率测试,1、关闭Read/Write功能会降低AssetBundle的物理大小,其降低量与资源本身数据量相关。同时,关闭Read/Write功能会大幅度降低网格资源的内存占用;2、关闭Read/Write功能会略微提升该资源的加载效率。
- 1、在保证视觉效果的前提下,尽可能采用“够用就好”的原则,即降低网格资源的顶点数量和面片数量;
- 2、研发团队对于顶点属性的使用需谨慎处理。通过以上分析可以看出,顶点属性越多,则内存占用越高,加载时间越长;
- 3、如果在项目运行过程中对网格资源数据不进行读写操作(比如Morphing动画等),那么建议将Read/Write功能关闭,既可以提升加载效率,又可以大幅度降低内存占用。
Unity Shader 加载模块
- Shader资源与之前的网格资源和纹理资源不同,其本身物理Size很小。Shader资源的效率加载瓶颈并不在其自身大小的加载上,而是在Shader内容的解析上.
- 1、Shader资源的物理体积与内存占用虽然很小,但其加载耗时开销的CPU占用很高,这主要是因为Shader的解析CPU开销很高,成为了Shader资源加载的性能瓶颈;
- 2、Mobile/Particles Additive在解析方面的耗时远小于Mobile/Diffuse、Mobile/Bumped Diffsue甚至Mobile/VertexLit;
- 3、除Mobile/Particles Additive外,其他三个(Mobile-Diffuse,Mobile-VertexLit,Mobile-Bumped Diffuse)主流Shader在加载时均会造成明显的降帧,甚至卡顿。因此,研发团队应尽可能避免在非切换场景时刻进行Shader的加载操作;
- 4、Mobile Shader较之同种Normal Shader在加载方面确实有一定的性能提升;
- 5、Shader的加载开销经常在几百甚至上千毫秒以上,其加载耗时居然要高于几张Atlas纹理或者拥有上万片面的Mesh网格!!
- Shader解析时的真正耗时原因
- 一般情况下,Shader加载的CPU耗时与其Keyword数量有关,Keyword数量越多,则加载开销也越大。Shader的Keyword数量是会随着场景设置的不同而变化的。在Unity 5.x中,Unity默认会根据场景设置、Shader Pass等来调整Shader的Keyword,比如如果存在Lightmap的使用,则会默认将对应的Keyword打开,而对于没有使用Fog的项目,则会直接将相关Keyword关闭。
- 对于Unity 5.x项目,可通过skip_variants操作在Shader中直接去除相关Keyword。
- 直接去除Shader中的Fallback选项。Fallback功能是对于无法使用当前Shader的硬件设备可以使用对硬件设备要求更低的Fallback Shader来进行渲染,以保证渲染的稳定性。
- Shader加载方式,5.x之后的Shader加载只是加载,加载之后还需要运行时编译,需要主动使用shader.WarmupAllShaders又或者ShaderVariantCollection.WarmUp来编译shader
- 大量相同Shader重复解析造成的。是因为Shader被打包到不同的AssetBundle文件中,每次切换场景时,AssetBundle均会被频繁地进行加载和卸载,从而造成了大量相同的Shader被重复加载和卸载。
- 1、通过依赖关系打包,将项目中的所有Shader抽离并打成一个独立的AssetBundle文件,其他AssetBundle与其建立依赖;并对其进行预加载,以降低后续不必要的加载开销。
- 2、Shader的AssetBundle文件在游戏启动后即进行加载并常驻内存,因为一款项目的Shader种类数量一般在50~100不等,且每个均很小,即便全部常驻内存,其内存总占用量也不会超过2MB;
- 3、后续Prefab加载和实例化后,Unity引擎会通过AssetBundle之间的依赖关系直接找到对应的Shader资源进行使用,而不会再进行加载和解析操作。
- 4、正在使用Resources.Load来加载资源的研发团队,可以尝试使用ShaderVariantCollection(着色器变体群,着色器资源列表,是一个由通道类型+着色器关键字组合的列表)来对Shader进行Preload,同样也可以达到避免相同Shader重复加载的效果。https://www.cnblogs.com/rexzhao/p/7884905.html
- 5、在生成时剔除多余着色器变体, 1)个别着色器特性,比如使用 #pragma shader_feature的着色器,如果没有材质使用到了这个特性,那么就不会把它打包进去;2)没有被任何场景使用到的雾效(Fog)或光照贴图模式(Lightmap)的着色器变体,也不会打包进去。
- 6.shader加载造成的卡顿有两种情况:1、着色器变种已经打包到APP中,只需要加载该变体,创建GPUProgram就可以了.2、着色器变种没用被打包,这时需要shaderlab文件进行解析和编译相应的变种,然后创建GUPProgram
Unity动画加载模块
- AnimationClip资源是项目运行时最常加载的资源之一,且其加载效率主要由其自身加载量决定,而决定AnimationClip资源加载量的主要因素则是它的压缩格式。
- Unity引擎对导入的AnimationClip提供三种压缩格式,Off、Keyframe Reduction和Optimal。Off表示不采用压缩处理;Keyframe Reduction表示使用关键帧进行处理,Optimal则表示Unity引擎会根据动画曲线的特点来自动选择一个最优的压缩方式,可能是关键帧压缩,也可能是Dense压缩。https://docs.unity3d.com/Manual/class-Animator.html
- Optimal压缩方式确实可以提升资源的加载效率,无论是在高端机、中端机还是低端机上;
- 硬件设备性能越好,其加载效率越高。但随着设备的提升,Keyframe Reduction和Optimal的加载效率提升已不十分明显;
- Optimal压缩方式可能会降低动画的视觉质量,因此,是否最终选择Optimal压缩模式,还需根据最终视觉效果的接受程度来决定。
Xcode 增量打包
https://blog.uwa4d.com/archives/USparkle_iOS.html
Overview 类型
- 1 Profiler中WaitForTargetFPS详解 https://blog.csdn.net/suifcd/article/details/50942686
该参数一般出现在 CPU开销过低,且通过设定了目标帧率的情况下(Application.targetFrameRate)。当上一帧低于目标帧率时,将会在本帧产生一个WaitForTargetFPS的空闲等待耗时,以维持目标帧率。
Gfx.WaitForPresent && Graphics.PresentAndSync
这两个参数在Profiler中经常出现CPU占用较高的情况,且仅在发布版本中可以看到。究其原因,其实是CPU和GPU之间的垂直同步(VSync)导致的,之所以会有两种参数,主要是与项目是否开启多线程渲染有关。当项目开启多线程渲染时,你看到的则是Gfx.WaitForPresent;当项目未开启多线程渲染时,看到的则是Graphics.PresentAndSync。
Graphics.PresentAndSync 是指主线程进行Present时的等待时间和等待垂直同步的时间。Gfx.WaitForPresent其字面意思同样也是进行Present时需要等待的时间,但这里其实省略了很多的内容。其真实的意思应该是为了在渲染子线程(Rendering Thread)中进行Present,当前主线程(MainThread)需要等待的时间。
当项目开启多线程程渲染时,引擎会将Present等相关工作尽可能放到渲染线程去执行,即主线程只需通过指令调用渲染线程,并让其进行Present,从而来降低主线程的压力。但是,当CPU希望进行Present操作时,其需要等待GPU完成上一次的渲染。如果GPU渲染开销很大,则CPU的Present操作将一直处于等待操作,其等待时间,即为当前帧的Gfx.WaitForPresent时间,如下图所示。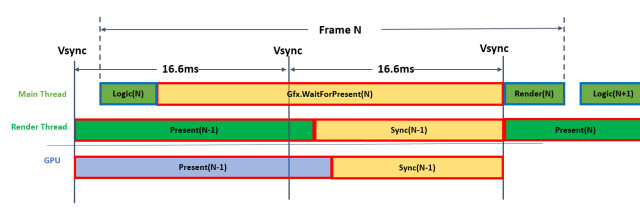
同理,当项目未开启多线程渲染时,引擎会在主线程中进行Present(当前绝大多数的移动游戏均在使用该中操作),当然,Present操作同样需要等待GPU完成上一次的渲染。如果GPU渲染开销很大,则CPU的Present操作将一直处于等待操作,其等待时间,即为当前帧的Graphics.PresentAndSync时间: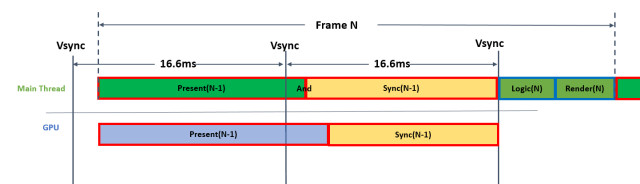
所以,如果你的项目中,Gfx.WaitForPresent或Graphics.PresentAndSync的CPU耗时非常高时,其实并不是它们自己做了什么神秘的操作,而是你当前的渲染任务太重,GPU负载过高所致。
同时,对于开启垂直同步的项目而言,Gfx.WaitForPresent 和 Graphics.PresentAndSync也会出现CPU占用较高的情况。在解释这种问题之前,我们先以“大家乘坐地铁”来举个例子。一般来说,地铁到达每一站的时间均是平均且一定的,假设每10分钟一班接走一批乘客。但是几乎没有多少乘客可以按点到达,如果提前两分钟到达,则只需要等待两分钟即可乘上地铁,但是,如果你错过了,哪怕只差了一分钟,那么你也不得不再等待九分钟才能乘上地铁。
上述的情况我们经常会遇到。在GPU的渲染流水线中,其转换front buffer和back buffer的工作原理和“乘坐地铁”其实是一致的。大家可以把GPU的流水线简单地想象成为一列地铁。对于移动设备来说,GPU的帧率一般为30帧/秒或60帧/秒,即VSync每33ms或每16.6ms“到站一次”,CPU的Present即为“乘客乘上地铁”,然后前往各自的目的地。与乘客的早到和晚到一样,CPU的Present也会出现类似的情况,比如:
● CPU端开销非常小,Present在很早即被执行,但此时VSync还没到,则会出现较高的等待时间,即Gfx.WaitForPresent 和 Graphics.PresentAndSync的CPU开销看上去很高。
● CPU端开销很高,使得Present执行时错过了VSync操作,这样,Present将不得不等待下一次VSync的到来,从而造成了Gfx.WaitForPresent 和 Graphics.PresentAndSync的CPU开销较高。这种情况在CPU端加载过量资源时特别容易发生,比如WWW加载较大的AssetBundle、Resource.Load加载大量的Texture等等。
通过以上的讲解,我们希望此刻的你已经对Gfx.WaitForPresent 和 Graphics.PresentAndSync已经有了深入的理解。这两个参数无论CPU占用多少,其实都不是这两个参数的自身问题,而是项目的其他部分造成。对此,我们做一个总结,以方便你进一步加深印象。
造成这两个参数的CPU占用较高的原因主要有以下三种原因:
● CPU开销非常低,所以CPU在等待GPU完成渲染工作或等待VSync的到来;
● CPU开销很高,使Present错过了当前帧的VSync,即不得不等待下一次VSync的到来;
● GPU开销很高,CPU的Present需要等待GPU上一帧渲染工作的完成。
最后,如何优化并降低这两个参数的CPU占用呢? 那就是,忽略Gfx.WaitForPresent 和 Graphics.PresentAndSync这两个参数,优化其他你能优化的一切!
UnityEngine.SetupCoroutine:InvokeMoveNext
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1487842110@qq.com
Title:Unity UWA工具检测优化
文章字数:12.9k
Author:诸子百家-谁的天下?
Created At:2020-05-08, 11:41:32
Updated At:2021-03-28, 02:59:27
Url:http://yoursite.com/2020/05/08/Unity/Optimize/UWA%E4%BC%98%E5%8C%96/Copyright: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

